
منذ قرابة عقد من الزمن، توصلت لقناعة وهي أن قراءة الأوراق البحثية هي أفضل طريقة لبناء فهم أعمق للمجالات التي أهتم بها كـ Distributed systems وللبقاء على إطلاع بما هو جديد. كما أن تقنيات كثيرة ومجالات في علوم الحاسب نأخذها الآن كأحد المسلّمات ولكن لو رجعنا الى تاريخها سنجد أنها بدأت بالغالب بسبب ورقة بحثية كمثال حراك البيانات الضخمة والأنظمة السحابية كـ Kubernetes.
تطورت الحالة لدي حتى قمت بقراءة كل ماهو جديد في مجالات اخرى مقاربة لإهتماماتي في هيكلة البيانات والخوارزميات، لم تكن بحثًا عن شيء بحد ذاته بقدر ماهو حب للإطلاع ومحاولة إيجاد طرق وأفكار جديدة أستقيها من هذه الأوراق حتى أُسقطها على المشاكل التي تواجهني بشكلٍ يومي. فعلى سبيل المثال، قرابة تلك الفترة وإبان إشتعال إهتمامي في Probabilistic Data-structures أتتني الفرصة بعدها بعدة أشهر أن أعمل على نظام يقوم بمعالجة لحظية لإحصائيات لنظام يستخدم في داخل عملي. وأستطعت أن أقوم ببناء هذا النظام الذي كان سيحتاج الى ميزانية ضخمة من أجل تحمّل ذلك العدد الى ميزانية لاتكلف إلا ١٠٪ من ذلك الرقم.
كانت هذه بفضل أنني توصلت الى نقطة تضحية بسيطة وهي أن في ذلك النوع من الاحصائيات يكفي جدًا ان يكون الرقم صحيح بنسبة ٩٩.٩٪ فلا يفرق إن زاد أو نقص الرقم بعدد.. مثلًا ماتفرق ١٠٠ عن ١٠١ مشاهدة. فعن طريق تجميع هيكلا البيانات Filtered Space-Saving و Count-min sketch كنت على استطاعة على تحليل من بناء أداة تقوم بتحليل بيانات مئات الجيجابايت بثواني دون الحاجة الى سعة تخزين عالية او RAM بمواصفات كبيرة. لن أطيل الحديث عن هذه الأداة حيث أنني سأقوم بالحديث عنها بشكل مسهب أكثر لاحقًا، ولكن الهدف هو أن تتضح لك أن قراءة الأوراق البحثية سيكون لها تأثير مباشر وملحوظ على عملك وقدرتك على حل مشاكل لم تتوقع أن بإمكانك حلها بطرق خلّاقة من قبل.
كيف تقرأ ورقة بحثية؟
أول مصدر أنصحك بقراءته هو هذه الورقة البحثية التي ستشرح لك كيف تقرأ الأوراق البحثية.
وأيضًا كخطوة إضافية شخصيًا أحاول في البداية البحث عن حديث مسجل عن الورقة من أحد الباحثين، لأنه غالبًا سيركز على الأفكار المهمة في الورقة البحثية ومحاولة إبرازها بشكل أوضح وأيضًا أحاول البحث عن تلخيص لها في أحد المدونات/المجتمعات التي ذكرتها بالأسفل.
نأتي الآن للسؤال الاخر وهو كيف أصل لأوراق بحثية مهمة ومفيدة، وهنا تختلف المصادر بحسب المجالات التي تهتم بها ولكن أشهرها مثلًا:
مجتمع Papers We Love
مدونة The Morning Paper
مدونة Murat
وطبعًا بناءً على المجال الذي تهتم به يوجد الكثير من المؤتمرات التي يتنافس الباحثين على النشر بها لذا أنصحك بالبحث والإطلاع عليها لاحقًا.
هذا مصدر جيّد لمعرفة بعض من أفضل المؤتمرات البحثية https://iiti.ac.in/people/~artiwari/cseconflist.html
بعض من الاختيارات لبعض المشاكل والاوراق التي اعجبتي وافادتني:
On designing and deploying internet-scale services
On designing and deploying internet-scale services - James Hamilton. 2007
هذه ورقة بحثية تحتوي عصارة تجربة أحد أعظم المبرمجين في تجربته في بناء خدمات انترنت في شركة ميكروسوفت، العجيب أن عدد كبير من النصائح المذكورة مؤخرًا أصبحت هي Best practices لأغلب الخدمات السحابة Cloud-Native، لازلت أذكر الشعور عند قرائتي للورقة لأول مرة في 2015 ومدى تأثيرها على كيف كنت أبني الأنظمة من بعدها. بالطبع ليس كل شيء مذكور بالورقة يجب تنفيذه فهنالك أشياء لا حاجة لها إلا إذا كنت تتعامل مع ملايين المستخدمين بالثانية الواحدة. ولكن تبقى ورقة مفيدة جدًا.
وهنا قائمة تحقق (Checklist) مبنية من النصائح في الورقة، بإمكانك إستخدامها للتحقق من الخدمات التي تقوم ببناؤها.
شطحة: الكاتب الان Distinguished Engineer في AWS وله أسلوب حياة شاطح.
للإستزادة:
The Power of Two Random Choices
The Power of Two Random Choices: A Survey of Techniques and Results Mitzenmacher et al. 2001
هذه الورقة تقدّم تكنيك مثبت وبسيط جدًا جدًا لمشاكل عميقة ومعقدة في Load Balancing، على سبيل المثال لنتخيل ان لديك خوادم موزعة حول العالم وتريد توزيع الطلبات بينهم للخادم الأقل استهلاكًا، لذا يستحيل أن تعرف حقًا من هو الأقل استهلاكًا لان فيزيائيًا المعلومات التي لديك دائمًا ستكون ليست الأحدث.
هذا يعني إن اضفت خادم جديد فجأة كل الطلبات من كل الـ Load Balancers ستذهب لهذا الخادم الجديد وهذا ما لا نريده، أحد الحلول السهلة لهذه المشكلة والتي تعرف بـ Thundering Herd هو بدلًا من أن تختار الأقل إستهلاكًا من كل الخوادم، تختار خادمين بشكل عشوائي ومن ثم تختار الأقل إستهلاكًا بينهما!
هذه الطريقة السهلة هي التي تستخدمها كبرى الشركات التقنية مثل CloudFlare، AWS, Facebook وغيرهم.
وأحد الإستخدامات اللطيفة التي وجدتها لهذا التكنيك هو في ورقة بحثية من فيسبوك عن نظامهم Scuba الذي يستخدمونه لحفظ بيانات حيوية عن أنظمتهم (Monitoring Metrics) فعند كتابة بيانات جديدة يقوم النظام بإختيار خادمين بشكل عشوائي ومن ثم يرسل البيانات للخادم الذي يحتوى على أكبر قدر شاغر من RAM. وعند القراءة يرسل الطلب لكل السيرفرات ويقوم بتجميعها بشكل Tree.
للإستزادة:
End-to-End Arguments in System Design
End-to-end arguments in system design – Saltzer, Reed, & Clark 1984

نشرت هذه الورقة في عام ١٩٨٤ وقدمت هذه الورقة مبدأ End-to-End الذي يستخدمه أغلب مطوري الشبكات لتحديد مكان وضع الضمانات/المزايا، وهل تكون جزء من الشبكة أم تبنى في مستوى أعلى منها أي في التطبيق ذاته. وتتحدث هذه الورقة عن كيفية أن بناء نظام بهندسة Layered أن المستويات السفلى إن احتوت على ضمانات (Guarantees) فإنك ستضطر في معظم الأحوال على إعادة بناؤوها في المستويات التي أعلى منها حتى تضمن معنىً آخر لها للتطبيق الذي تبنيه مما سيضر أداء التطبيق. تفترض الورقة أنك تريد بناء تطبيق نقل ملفات فمثلًا لنقل أنك سترسل ملف كبير بين جهازين، بإستخدام TCP والتي تضمن ترتيب الرسائل، لكن المشكلة هنا ضمان الترتيب في TCP له معنى مختلف فهذا البروتوكول لا يعي أنك تقوم بإرسال ملف كبير أكبر من الرسائل التي يحتويها ويفهمها هذا المستوى وأنك تقوم بتوزيعه على عدة أقسام Chunks لذا ستضطر لإعادة بناء هذا الشيء في تطبيقك مما يعني أنك أعدت بناء العجلة بطريقة أو بأخرى، فمثلًا لو استخدمت UDP لربما ستحصل على نتائج أسرع وأفضل. الورقة تقدّم هذا المبدأ كإقتراح للمبرمجين عند بناء نظام يستخدم Layered Architecture كمثال TCP/IP وأيضًا HTTP Servers.
وبعد ٢٠ عام من نشرها تم نشر ورقة بحثية أخرى بعنوان:
A critical review of “End-to-end arguments in system design” - Tim Moors 2002
تعيد النظر فيها وقدمت إقتراحين آخرين لتحديد مكان وضع الضمانات/المزايا وهما الثقة والمسؤولية (Responsibility & Trust) فمثلًا إن كنت لاتثق في الجهة المقابلة لك فهذا يعني أنها مسؤوليتك للتأكد من كل شيء يأتيك.
للإستزادة:
End-to-end arguments in system design – Saltzer, Reed, & Clark 1984
A critical review of “End-to-end arguments in system design” - Tim Moors 2002
Filtered Space Saving
Finding top-k elements in data streams - Nuno Homem , Joao Paulo Carvalho. 2010
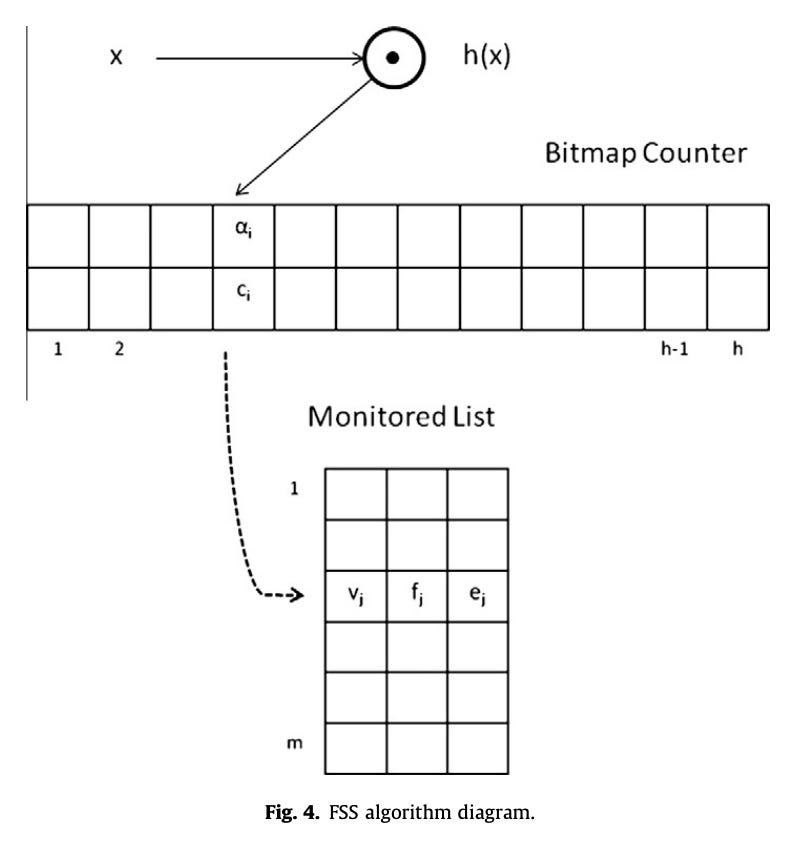
تخيّل معي أن لديك متجر يستخدمه ويزوره ١٠ ملايين مستخدم يوميًا، وتود إضافة ميزة تقديم خصومات لأكثر ٢٠ مستخدم زيارةً لمتجرك. الحل هنا دون تفكير أنك غالبًا ستقوم بإضافة كل زيارة في قاعدة بيانات ومن ثم تقوم بكتابة SQL Query تقوم بجمع الزيارات لكل مستخدم ومن ثم ترتيبها من الأعلى للأقل وحدّها الى ٢٠ فقط. مشكلة هذا الحل أن الأداء فيه يتأثر كلما إزداد عدد المستخدمين بالرغم من اننا نريد فقط ٢٠ شخص فقط وهذا عدد بسيط. ماتقدم FSS هو حل مختلف لا يعتمد على العدد الكلي للمستخدمين ولكن العدد الذي تريد متابعته وهو ٢٠. لذا المساحة فيه دائمًا ثابته ومعرفة من قبل، ولكي تصل لهذا الحل هي تقوم بتلخيص البيانات التي تصلها وبناء مايعرف بـ Data Sketch يقدم ضمانات معينة تتماشى مع مانريده.
وكحال أي تلخيص فهنالك تضحية مابين دقة الأجوبة وسعة التخزين. الجميل جدًا في ضمانات هذا الهيكل هي أنها رغم أنها لاتتبع الا العدد لـ ٢٠ إلا انها تضمن أنهم فعلًا الأعلى. طبعًا أنصحك بقراءة الورقة وتلخيصها. كما أنصحك بقراءة Count-Min Sketch أولًا.
للإستزادة:
ختامًا
في حال أعجبتك النشرة شاركها مع من تهمهم، وتابعنا على تويتر